
En esta serie de dos publicaciones, aprenderá a monitorear servicios sin servidor con CloudWatch mediante la creación de paneles, widgets y alarmas con AWS CDK.
En esta publicación, aprenderá qué significa monitorear un servicio sin servidor, por qué es esencial y cómo crear paneles de CloudWatch para monitorear su servicio sin servidor con widgets. Los widgets muestran información de registros de CloudWatch, métricas, métricas personalizadas y definen alarmas de CloudWatch como parte de un enfoque proactivo.
En la segunda parte de la serie, utilizaremos AWS CDK para monitorear un servicio sin servidor de muestra y crear los paneles presentados en la primera publicación de la serie.
Tabla de contenido
¿Qué significa supervisar aplicaciones sin servidor?
Así que ya creaste tu servicio sin servidor y lo pusiste en funcionamiento. ¡Genial!
Sin embargo, nada es infalible y es solo cuestión de tiempo hasta que surja un error o un problema de producción.
"Salud del servicio" es una expresión que hace referencia al estado operativo, la disponibilidad y el rendimiento de un servicio, garantizando que funcione correctamente y brinde la experiencia de usuario esperada. Por eso, necesitamos una solución de monitoreo que brinde visibilidad crucial para comprender el estado de salud actual y futuro de nuestro servicio. Ahí es donde entran en juego los paneles de control de CloudWatch. Son una solución esencial para monitorear el estado de salud de los servicios sin servidor.
Los paneles de control facilitan la comprensión del estado actual del servicio y la reacción en consecuencia.
Los paneles de estado del servicio CloudWatch muestran información diferente en widgets. Cada widget muestra registros, alarmas o información de métricas personalizadas de CloudWatch.
CloudWatch proporciona numerosas métricas para muchos servicios sin servidor de manera predeterminada, pero los registros y las métricas personalizadas requieren una implementación específica. Si desea conocer las mejores prácticas de observabilidad, consulte mis blogs anteriores sobre seguimiento, registros y métricas:
Por dónde empezar
Nuestro objetivo final es descubrir cualquier problema potencial, ya sea un error o un problema de configuración que resulte en una degradación del rendimiento antes de que cualquier cliente se dé cuenta o se vea afectado por el problema.
Queremos supervisar el rendimiento y los errores. El control del rendimiento se logra con las métricas de CloudWatch. Los errores se pueden controlar tanto con las métricas de CloudWatch como con los registros de servicio. Y, por último, las alarmas de CloudWatch contribuirán al enfoque proactivo y nos alertarán de cualquier catástrofe inminente.
Al crear un nuevo panel de monitoreo para un servicio, sigo estas pautas:
Identifique los flujos críticos de su servicio y analice sus componentes sin servidor y funciones Lambda. Intente pensar: ¿cómo puedo saber si mi flujo crítico está a punto de fallar o tiene errores? ¿Puedo usar mensajes de registro o métricas específicas?
Abra el explorador de métricas de la consola de CloudWatch: busque las métricas que CW proporciona de manera predeterminada para cada servicio sin servidor que pertenece a su ruta crítica. Piense detenidamente en qué métricas brindan la mayor información para resolver errores rápidamente.
Identifique si las rutas críticas son solo de lectura y escritura. Existen diferentes métricas para las operaciones de lectura y escritura en DynamoDB y otras bases de datos sin servidor. Concéntrese en las métricas que sean importantes para usted.
Sobrecarga de información: trate de no agregar todas las métricas posibles. Un tablero con demasiada información es un tablero que nadie usa. Los tableros deben ser simples y fáciles de usar. Un simple vistazo debería brindarle la información que necesita.
Adapte el panel o los paneles a la persona que los utiliza. Presentaré un enfoque de panel de múltiples capas (más información sobre esto a continuación).
Administra el panel de control de monitoreo con infraestructura como código. Administrarlos con código los hace reutilizables en múltiples equipos y servicios. Además, si se eliminan por error, tienes un método seguro para restaurarlos.
Defina las alarmas de CloudWatch sobre problemas críticos (más sobre esto más adelante).
Utilice los colores del tablero para enfatizar el tipo de información: errores como el rojo, etc.

Ahora que entendemos la teoría, convirtamos la teoría en práctica y monitoreemos un servicio sin servidor de muestra: el servicio "pedidos".
El servicio de pedidos sin servidor

El servicio 'pedidos' proporciona una API REST para que los clientes creen pedidos de artículos.
El servicio implementa un API Gateway con una integración de AWS Lambda en la ruta '/api/orders/' y almacena los datos de los pedidos en una tabla de DynamoDB. Tiene características avanzadas como la idempotencia (más información aquí ) en forma de una segunda tabla de DynamoDB y capacidades de indicadores con AWS AppConfig (más información aquí ).
Puedes encontrar el código completo aquí .
Analicemos la ruta crítica del servicio.
La ruta crítica es la función Lambda "crear pedido". Entendemos que nuestra ruta crítica es escribir pedidos en la tabla DynamoDB, por lo que necesitamos monitorear las métricas de escritura de DynamoDB y monitorear la tasa de errores de API Gateway. Además, queremos asegurarnos de que nuestros clientes tengan una buena experiencia, por lo que el monitoreo del tiempo total de operación es esencial.
Creación de paneles de CloudWatch
Diferentes personas que prestan servicios utilizan paneles de monitoreo por diversos motivos.
Repasemos nuestras personas:
Los ingenieros de confiabilidad del sitio y los equipos de soporte necesitan información para diagnosticar rápidamente los problemas de servicio y solucionarlos o escalarlos al equipo de desarrollo. Los SRE y los equipos de soporte están familiarizados con el servicio en el nivel superior (pero a veces en un nivel más profundo) y, en muchos casos, están a cargo de varios servicios.
Desarrolladores de servicios: el equipo que crea y mantiene el servicio. Son los expertos en servicios.
Miembros del equipo de productos: interesados en saber si los usuarios obtienen la experiencia prometida. Controlan las métricas de KPI para comprender el uso del servicio.
Como puede ver, cada persona ve y supervisa el servicio de forma diferente. Por ello, crearemos varios paneles de control para satisfacer sus responsabilidades y requisitos.
Definiremos dos cuadros de mando: uno de alto nivel y otro de bajo nivel.
Panel de control de alto nivel
Este panel está diseñado para ser una descripción general del monitoreo ejecutivo del servicio.
El panel de control proporciona una descripción general simple que no requiere una comprensión profunda de la arquitectura del servicio.
En nuestro caso, se centra en las métricas de AWS API Gateway tanto para el rendimiento general (latencia) como para las tasas de error (códigos de respuesta HTTP 4XX o 5XX).
La latencia de API GW se define como "el tiempo entre cuando API Gateway recibe una solicitud de un cliente y cuando devuelve una respuesta al cliente" - Documentación de AWS .
Esta métrica marca el tiempo total que tarda un usuario en crear un pedido y obtener una respuesta. Tenga en cuenta que monitoreamos las métricas de percentiles promedio P50, P90 y P99 (más información sobre esto más adelante).
Las métricas de KPI también se incluyen en la parte inferior, lo que satisfará las necesidades de los equipos de productos. Cuentan la historia del uso del usuario, que es fundamental para el éxito del servicio. En nuestro servicio, una métrica de KPI se definió como la cantidad de solicitudes de "creación de pedidos" válidas .
Personas que utilizan este panel: SRE, desarrolladores y equipos de productos (KPI)

Tenga en cuenta que puede agregar un widget de registro que filtre solo los mensajes de "Error". Elegí agregarlo en el panel de nivel inferior.
Además, he definido alarmas de CloudWatch con respecto a la tasa de errores de API Gateway (como lo indica la tasa de errores 5XX de la línea roja en el widget de tasa de errores), pero hablaremos más sobre eso a continuación.
Panel de control de bajo nivel
El segundo panel que creamos ofrece un análisis profundo de todos los recursos del servicio: sus métricas y registros. Por lo tanto, navegar por los widgets del panel requiere una mejor comprensión de la arquitectura del servicio.
El panel muestra las métricas de la función Lambda (función 'crear orden') para el tiempo de duración total (está etiquetada como latencia, pero es duración), errores, limitaciones, simultaneidad aprovisionada e invocaciones totales.
Además, un widget de registros de CloudWatch muestra solo los registros "ERROR" de la función Lambda. Cada registro contendrá un ID de correlación que ayuda a encontrar otros registros de la misma sesión al depurar un problema.
En cuanto a las tablas de DynamoDB, tenemos la base de datos principal y la tabla de idempotencia.
Los monitoreamos para verificar su uso, latencia en las operaciones de lectura/escritura, errores y limitaciones.
Personas que utilizan este panel: desarrolladores y, a veces, SRE.


La duración media no lo dice todo
La duración promedio no cuenta la verdadera historia de la duración.
Es un juego de números. En promedio, la duración de la función "crear pedido" puede ser aceptable para todos los usuarios, pero para algunos usuarios, quizás un pequeño porcentaje, la duración puede ser terrible. Ahí es donde entran en juego las métricas de percentiles: métricas para P99, P90, etc.
Tomemos como ejemplo P99:
El percentil 99 (abreviado como p99) indica que el 99% de la muestra está por debajo de ese valor y el resto de los valores (es decir, el otro 10%) están por encima de él - Abstracta ES
Eso significa que el 1 % de sus usuarios podría tener una mala experiencia. Puede que no suene tan mal, pero en el contexto de una empresa con mil millones de usuarios como Facebook, eso se traduce en millones de usuarios frustrados.
Alarmas de CloudWatch
Tener visibilidad e información es una cosa, pero ser proactivo y saber de antemano que se avecina un error importante es otra.
Una alarma de CloudWatch es una herramienta de notificación automatizada dentro de AWS CloudWatch que activa alertas basadas en umbrales definidos por el usuario, lo que permite a los usuarios identificar y responder a problemas operativos, infracciones o anomalías en los recursos de AWS mediante el monitoreo de métricas específicas durante un período designado.
En nuestros paneles de control encontrarás ejemplos de dos tipos de alarmas:
Alarma para monitoreo del umbral de rendimiento (duración o latencia)
Alarma para monitorización del umbral de tasa de error
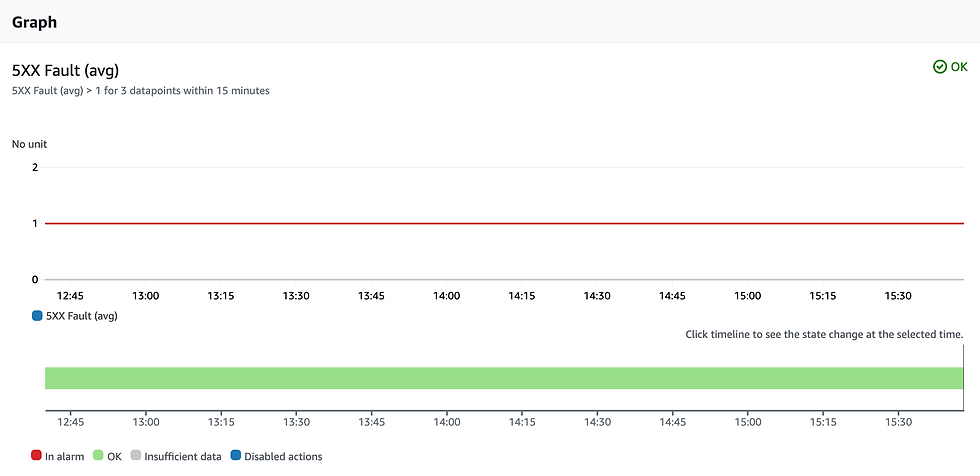
Alarma de tasa de error
El código HTTP 5XX significa un error interno del servidor. Este error nunca debería ocurrir. Es una señal de que ha ocurrido algo inesperado; puede ser una interrupción o un problema de AWS o un error en el código.
He definido el umbral aquí como un error 5XX en el transcurso de 15 minutos, pero puedes definirlo como quieras (puede que haya sido demasiado estricto).
Alarma basada en duración
Para problemas basados en la duración, definimos la siguiente alarma en la duración P90 para la función Lambda "crear pedido". La duración promedio de la función Lambda "crear pedido" es de 2 segundos, por lo que establezco el umbral de la alarma en 3 segundos (3000 ms). Tenga en cuenta que debe cubrir otras distribuciones, no solo P90: P99, P95 y promedio, si desea brindar la mejor experiencia de usuario a TODOS sus usuarios.

Tenga en cuenta que puede cambiar el widget para mostrar un valor numérico singular en lugar de un gráfico.
Acciones de alarmas
Las alarmas no sirven de nada a menos que tengan una acción cuando se activan.
Hemos configurado las alarmas para enviar una notificación de redes sociales a un nuevo tema de redes sociales. Desde allí, puedes conectar cualquier suscripción (HTTPS, SMS, correo electrónico, etc.) para notificar a tus equipos los detalles de la alarma para que puedan reaccionar y resolver el problema.
Reaccionando a las alarmas
Cuando descubrimos posibles problemas de rendimiento en servicios sin servidor, principalmente funciones Lambda, la solución es diferente a la que teníamos en el "viejo" mundo: no se reinicia un servidor, no se administra la infraestructura subyacente y cada problema requiere una investigación exhaustiva del volumen de tráfico, la entrada del usuario y la configuración de Lambda.
Además, cada solución requiere una implementación de canalización CI/CD, ya sea para actualizar la configuración de la función o el código (no realice cambios manuales en producción).
Resumen y código CDK
Con esto concluye la primera parte de la publicación sobre monitoreo. Hemos cubierto qué es el monitoreo de servicios sin servidor, nuestra metodología para crear un panel de control y creamos un panel de control para un servicio de muestra.
En la segunda parte de esta serie de blogs, repasaremos el código AWS CDK que creó estos paneles y alarmas.
Para aquellos que quieran ver el código ahora mismo, diríjanse aquí .