

Lambda function cold starts have intrigued countless AWS heroes and developers alike. Some swear they are a real issue today, while others frown and disregard them as not relevant anymore. However, from my experience, there are use cases where cold starts can impact user experience and must be dealt with.
In this post, you will learn what are cold starts, whether cold starts are still an issue, and best practices to reduce them.
TL;DR: Yes, but the context matters.
What's a Cold Start?
Cold starts in AWS Lambda occur when an AWS Lambda function is invoked after not being used for an extended period, or when AWS is scaling out function instances in response to increased load. - AJ Stuyvenberg, serverless hero
A lambda cold start refers to the initial delay experienced when an AWS Lambda function is invoked for the first time or after being idle, as the function's runtime environment is initialized. This includes downloading the function code and starting the execution environment.
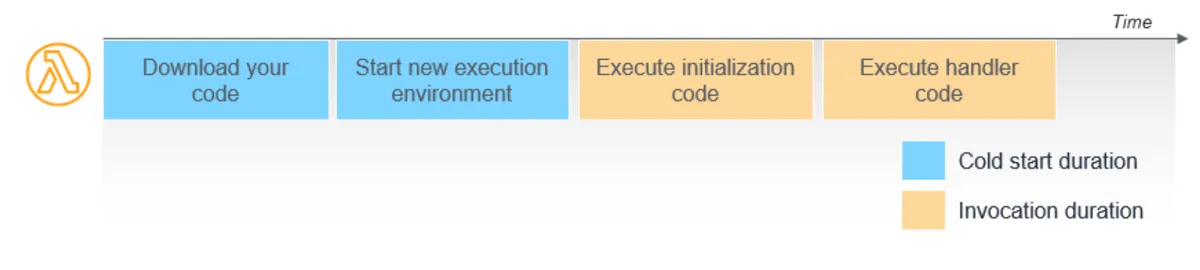
In a nutshell, it's an added one-time latency to the overall execution time of your function. The duration of a cold start varies from under 100 ms to over 1 second, according to the official AWS documentation. Once the function is "warm," further invocations will not suffer the cold start unless, due to traffic demands, the Lambda service increases the number of concurrent executions, resulting in new lambda functions invocations and cold starts.
In addition, when updating the function's code, you will get a cold start again during its invocation.
Now that we understand the technical definition of cold starts, let's talk about impact.
How bad is it really?
Lambda Cold Start Impact
According to an analysis of production Lambda workloads, cold starts typically occur in under 1% of invocations. - AWS
One percent doesn't sound like much, does it? Well, if you have a critical use facing synchronous flow and millions of invocations, that 1% now translates to potentially ten thousand unhappy customers, which is not ideal.
However, it's all very subjective and context matters, as there are use cases where this is just fine.
Let's start with the simple cases, the use cases where a cold start is probably fine.
Minor Impact Use Cases
Let's get the simplest use case out of the way: cases where the cold starts are so fast that it's not an issue for you. That's usually the case for function that use runtimes such as C++, Go, Rust, and LLRT. However, you must follow the best practices and optimizations in every runtime to maintain a low impact cold start.
Async Invocation
Another simple use is where your function gets invoked asynchronously, whether it's an SQS, SNS, EventBridge, DynamoDB stream, etc. In such use cases, another second of runtime is likely okay and not a deal breaker.
Non Critical Flow
Does a 0.5-1 second extra latency matter in noncritical flows for 1% of customers? Most likely not, especially if it's a non-customer facing flow like service-to-service calls.
However, some customer-facing actions might also be okay with the occasional cold start.
It depends on the total time: Will a customer notice the difference between 2 seconds and 1 second? Maybe, but it might be okay for most.
On the other hand, if the customer is waiting 5 seconds and now might have to wait 6 or 7, that might be quite noticeable as the customer is already waiting a long time, and extra time can increase annoyance.
Traffic Pattern
Your traffic behavior also plays a part. If you have constant traffic without dramatic scaling changes, you might not experience any cold starts as there are always warm functions.
Major Impact Use Cases - This is Where It Hurts
Let's review the use cases from my experience where cold starts had too much impact on user experience, and we had to take action to minimize them.
Critical Performance is a Must
Cold starts hurt the most when dealing with customer-facing flows where performance is critical, even for those 1% of customers. For example, if you have micro-services dedicated to authentication or authorization which are required to operate at a high concurrency and finish execution in less than a dozen milliseconds, 1% of an extra 0.5-1 second can be a deal breaker. I would argue that Lambda might be too expensive or unsuitable for such use cases, so do your research.
Erratic Traffic Pattern
The 1% magic numbers AWS provided might be different in your case, depending on the traffic pattern. If traffic is erratic, all over the place, and unpredictable, your function might have more cold starts than average.
Chained Cold Starts
Let's review the architecture below. You have three micro-services, each containing one Lambda function.
The user send an API request to the first function (1). The first function calls micro-service (2) and then calls the third (3).
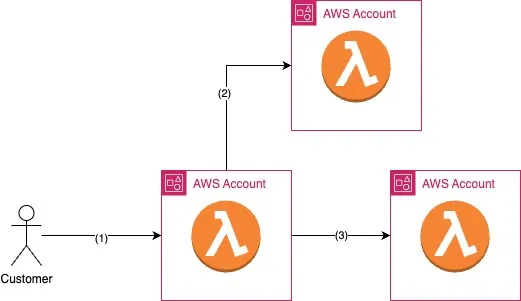
The first micro-service is waiting for both micro-services to respond, so its total runtime depends on their performance. Let's assume that the first micro-service had a cold start of 1 second, but when it called the second micro-service, it, too, had a cold start of one second. This happened again when it called the third service.
So now we have in total a 3-second cold start, which is quite bad from a user experience perspective.
It depends on your traffic patterns, but it can happen. You can get anywhere from zero, one, two, or three seconds cold starts durations; everything is a fair game. The problem becomes even more challenging when different teams manage the micro-services, each responsible for defining their functions and optimizations.
The bottom line is that every lambda function you depend on in a critical flow increases the chance of an aggregated cold start penalty, and you should consider that in advance.
How to Reduce Cold Start & Optimizations
Cold starts may discourage people from using serverless, and I can understand where those people are coming from, but it's not black and white. Cold starts can be improved and optimized to the point where they might not be relevant to your use cases.
Many parameters can reduce or increase the cold start duration, and it's essential to understand them. Let's list the most critical factors.
Function Memory Size
More memory translates to more CPU cores and better performance, which in turn can shorten cold start duration. However, your overall cost will increase. Use tools like AWS Lambda Powertuning to finetune performance to cost ratio.
CPU Architecture
Choosing an ARM64 CPU architecture can increase overall performance in some cases. Use Lambda Powertuning to check if there's a difference in your function.
Function Runtime
Different runtimes have different cold start performance. Java is notoriously slow, but it might be improved with SnapStart.
You can select Rust or LLRT (lambda low latency runtime) for the shortest cold starts.
For Rust-related content, I suggest you follow Benjamin's Pyle content.
AJ summarised the differences between runtime quite neatly (look for the snow icon as the cold start measurement):
Function Creation Method
AJ discusses this discrepancy in his re: invent session (see video below).
You can create a ZIP file containing all your Lambda function's dependencies and source code and upload it to AWS, or you can create a container image that contains everything it needs.
The container-based functions have shorter cold starts. However, I wouldn't change all my ZIP creations to containers just yet. Container based functions suffer from longer build and deployment time, and it's harder to manage (docker files are not fun). I'd use it only if I want the best performance or my function has dependencies over 250MB, which is the ZIP method limitation.
You can read more about it in my blog post on building Lambda container images with CDK.
Imports Matter
Developers tend to add imports that bring entire libraries just for a tiny function.
Every minor detail matters and adds to the total import time as part of the cold start. We need to optimize our code and imports. If you use Python, you can analyze your code with a tool like Tuna and optimize your libraries (perhaps replace slower ones) and your imports.
However, no matter how optimized your code is, you will suffer at some point from cold starts.
Let's discuss another solution that can go beyond optimizations.
As a side note, I highly recommend AJ's re:invent 2023 session if you want to dive really deep into Lambda and understand cold starts.
Provisioned Concurrency Solution
Let's assume you have done all the possible optimizations I've listed above, but you still experience meaningful cold starts in your customer-facing critical flows.
Your next solution will be to configure provisioned concurrency for your Lambda functions. Provisioned concurrency is the
number of pre-initialized execution environments allocated to your function. These execution environments are ready to respond immediately to incoming function requests. Configuring provisioned concurrency incurs additional charges to your AWS account. - AWS docs
Pay for always-warm functions—no more cold starts. Yes, it works, and it's expensive.
However, it's not magic. If you define 10 functions for provisioned concurrency and the Lambda service needs to scale to the 11th function due to traffic requirements and scale, you will get a cold start in that 11th function and beyond. However, if you fine-tune the number of provisioned concurrency so it fits your scaling needs, there should be zero cold starts (unless you upload a new lambda source code, of course).
The only issue with provisioned concurrency is that it can get quite expensive quickly. Imagine you enable it on multiple accounts and multiple regions; the cost multiplies quickly. I once got it wrong in the AWS pricing calculator, and the actual cost was much higher than what I anticipated, so we had to dial it down quickly.
In this post, we describe how you can optimize provisioned concurrency even further and enable a dynamic provisioned concurrency - an approach that maximizes performances while reducing cost.
Cost Optimizations
First, define provisioned concurrency only on your extremely user-facing, must-have-best-performance use cases. Even then, make sure you define it only in production account and not in the development or testing accounts.
Another cost-saving best practice is setting different concurrency settings for various accounts and regions. AWS recommends estimating the required settings; you can read their provisioned concurrency estimation formula.
Lastly, once configured, monitoring and alerts are required to ensure that you are not overspending or underspending. You can follow this AWS guide to understand how to build your alerts and dashboard.
Summary
In this post, we have defined cold starts and discussed their impacts - when they can hurt and when they mostly don't.
We've discussed how to optimize and minimize cold start impact, and when all optimizations have failed, the suggested but costly solution is to enable provisioned concurrency.
In the next post in the series, we will provide a cost optimization for provisioned concurrency along CDK code examples.


