
Nesta série de duas postagens, você aprenderá a monitorar serviços sem servidor com o CloudWatch criando painéis, widgets e alarmes com o AWS CDK.
Nesta publicação, você aprenderá o que significa monitorar um serviço serverless, por que isso é essencial e como criar dashboards do CloudWatch para monitorar seu serviço serverless com widgets. Os widgets exibem informações de logs do CloudWatch, métricas, métricas personalizadas e definem alarmes do CloudWatch como parte de uma abordagem proativa.
Na segunda parte da série, usaremos o AWS CDK para monitorar um serviço sem servidor de exemplo e criar os painéis apresentados no primeiro post da série.
Índice
O que significa monitorar aplicativos sem servidor
Então você construiu seu serviço serverless e entrou em produção. Ótimo!
No entanto, nada é infalível, e é apenas uma questão de tempo até que um bug ou problema de produção apareça.
"Service Health" é uma expressão que se refere ao status operacional, disponibilidade e desempenho de um serviço, garantindo que ele esteja funcionando corretamente e fornecendo a experiência esperada do usuário. É por isso que precisamos de uma solução de monitoramento que forneça visibilidade crucial para entender o status de saúde atual e futuro do nosso serviço. É aí que os painéis do CloudWatch entram em cena. Eles são uma solução essencial de monitoramento de saúde de serviço sem servidor.
Os painéis facilitam a compreensão do status atual do serviço e a reação adequada.
Os painéis de saúde do serviço CloudWatch exibem informações diferentes em widgets. Cada widget exibe logs do CloudWatch, alarmes ou informações de métricas personalizadas.
O CloudWatch fornece inúmeras métricas para muitos serviços serverless prontos para uso, mas logs e métricas personalizadas exigem implementação específica. Se você quiser aprender as melhores práticas de observabilidade, confira meus blogs anteriores sobre rastreamento, logs e métricas:
Por onde começar
Nosso objetivo final é descobrir qualquer problema potencial, seja um bug ou uma questão de configuração que resulte em degradação do desempenho antes que qualquer cliente tome conhecimento ou seja afetado pelo problema.
Queremos monitorar o desempenho e os erros. O monitoramento do desempenho é obtido com métricas do CloudWatch. Erros podem ser monitorados com métricas do CloudWatch e logs de serviço. E, por último, os alarmes do CloudWatch contribuirão para a abordagem proativa e nos alertarão sobre qualquer catástrofe iminente.
Ao criar um novo painel de monitoramento para um serviço, sigo estas diretrizes:
Identifique os fluxos críticos em seu serviço e analise seus componentes serverless e funções Lambda. Tente pensar: como posso saber se meu fluxo crítico está prestes a quebrar ou tem erros? Posso usar mensagens de log ou métricas específicas?
Abra o CloudWatch console metrics explorer - procure métricas que o CW fornece prontas para uso para cada serviço serverless que pertence ao seu caminho crítico. Pense cuidadosamente sobre quais métricas fornecem mais insights para resolução rápida de erros.
Identifique se os caminhos críticos são somente leitura/gravação. Há métricas diferentes para operações de leitura/gravação no DynamoDB e outros bancos de dados serverless. Concentre-se nas métricas que são importantes para você.
Sobrecarga de informações - tente evitar adicionar todas as métricas possíveis. Um painel com muita informação é um painel que ninguém usa. Os painéis precisam ser simples e fáceis de usar. Uma simples olhada deve fornecer as informações de que você precisa.
Adapte o painel ou painéis à persona que o usa. Apresentarei uma abordagem de painel multicamadas - mais sobre isso abaixo.
Gerencie o painel de monitoramento com infraestrutura como código. Gerenciá-los com código os torna reutilizáveis em várias equipes e serviços. Além disso, se eles forem excluídos por engano, você tem um método seguro para restaurá-los.
Defina alarmes do CloudWatch sobre problemas críticos (mais sobre isso depois).
Use as cores do painel para enfatizar o tipo de informação: erros como vermelho etc.

Agora que entendemos a teoria, vamos transformá-la em prática e monitorar um serviço sem servidor de exemplo, o serviço "pedidos".
O serviço sem servidor de pedidos

O serviço 'pedidos' fornece uma API REST para os clientes criarem pedidos de itens.
O serviço implementa um API Gateway com uma integração AWS Lambda no caminho '/api/orders/' e armazena dados de pedidos em uma tabela DynamoDB. Ele tem recursos avançados como idempotência (leia mais sobre isso aqui ) na forma de uma segunda tabela DynamoDB e recursos de recursos de sinalizadores com AWS AppConfig (leia mais sobre isso aqui ).
Você pode encontrar o código completo aqui .
Vamos analisar o caminho crítico do serviço.
O caminho crítico é a função Lambda 'create order'. Entendemos que nosso caminho crítico é escrever pedidos na tabela do DynamoDB, então precisamos monitorar as métricas de gravação do DynamoDB e monitorar a taxa de erro do API Gateway. Além disso, queremos ter certeza de que nossos clientes tenham uma boa experiência, então o monitoramento do tempo total de operação é essencial.
Construindo painéis do CloudWatch
Diferentes personas de serviço usam painéis de monitoramento por vários motivos.
Vamos rever nossas personas:
Engenheiros de confiabilidade do site/equipes de suporte precisam de informações para diagnosticar rapidamente problemas de serviço e corrigi-los ou encaminhá-los para a equipe de desenvolvimento. SREs/equipes de suporte estão familiarizados com o serviço em um nível mais alto (mas às vezes em um nível mais profundo) e, em muitos casos, são responsáveis por vários serviços.
Desenvolvedores de serviço - a equipe que constrói e mantém o serviço. Eles são os especialistas em serviço.
Membros da equipe de produto - interessados em saber se os usuários obtêm a experiência de usuário prometida. Eles monitoram métricas de KPI para entender o uso do serviço.
Como você pode ver, três personas veem e monitoram o serviço de forma diferente. Como tal, construiremos vários dashboards para atender às suas responsabilidades e requisitos.
Definiremos dois painéis: de alto nível e de baixo nível.
Painel de alto nível
Este painel foi criado para ser uma visão geral do monitoramento executivo do serviço.
O painel fornece uma visão geral simples que não exige uma compreensão profunda da arquitetura do serviço.
No nosso caso, ele se concentra nas métricas do AWS API Gateway para desempenho geral (latência) e taxas de erro (códigos de resposta HTTP 4XX ou 5XX).
A latência do API GW é definida pelo "tempo entre o momento em que o API Gateway recebe uma solicitação de um cliente e o momento em que ele retorna uma resposta ao cliente" - Documentação da AWS .
Esta métrica marca o tempo total que um usuário leva para criar um pedido e obter uma resposta. Observe que monitoramos as métricas de percentis médios, P50, P90 e P99 - mais sobre isso depois.
Métricas de KPI também estão incluídas na parte inferior, o que atenderá às necessidades das equipes de produto. Elas contam a história do uso do usuário, o que é crítico para o sucesso do serviço. Em nosso serviço, uma métrica de KPI foi definida como o número de solicitações válidas de 'criar pedido'.
Pessoas que usam este painel: SRE, desenvolvedores e equipes de produtos (KPIs)

Observe que você pode adicionar um widget de log que filtra apenas mensagens de 'Erro'. Eu escolhi adicioná-lo no painel de baixo nível.
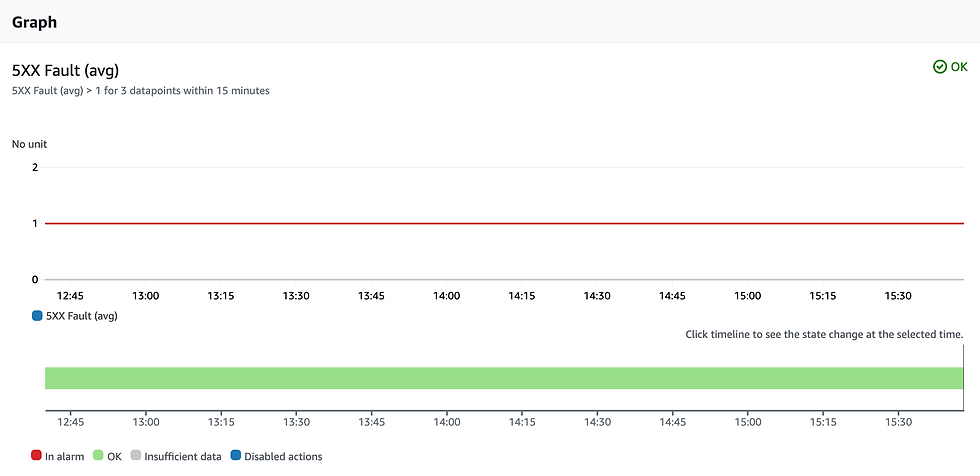
Além disso, defini alarmes do CloudWatch em relação à taxa de erro do API Gateway (conforme observado pela taxa de falha da linha vermelha 5XX no widget de taxa de erros), mas falaremos mais sobre isso abaixo.
Painel de baixo nível
O segundo painel que construímos fornece um mergulho profundo em todos os recursos do serviço: suas métricas e logs. Como tal, navegar pelos widgets do painel requer um melhor entendimento da arquitetura do serviço.
O painel exibe as métricas da função Lambda (função 'criar pedido') para tempo de duração total (é rotulado como latência, mas é duração), erros, limitações, simultaneidade provisionada e invocações totais.
Além disso, um widget de logs do CloudWatch mostra apenas logs 'ERROR' da função Lambda. Cada log conterá um ID de correlação que ajuda a encontrar outros logs da mesma sessão ao depurar um problema.
Quanto às tabelas do DynamoDB, temos o banco de dados primário e a tabela de idempotência.
Nós os monitoramos quanto ao uso, latência de operação de leitura/gravação, erros e limitações.
Personas que usam este painel: desenvolvedores e, às vezes, SREs.


A duração média não diz tudo
A duração média não conta a história real da duração.
É um jogo de números. Em média, a duração da função 'criar pedido' pode ser aceitável para todos os usuários, mas para alguns usuários, talvez uma pequena porcentagem, a duração pode ser terrível. É aí que as métricas de percentil entram em jogo - métricas para P99, P90, etc.
Vamos pegar o P99 como exemplo:
o percentil 99 (abreviado como p99) indica que 99% da amostra está abaixo desse valor e o restante dos valores (ou seja, os outros 10%) estão acima dele - Abstracta US
Isso significa que 1% dos seus usuários pode ter uma experiência ruim. Pode não parecer tão ruim, mas no contexto de uma empresa de bilhões de usuários como o Facebook, isso se traduz em milhões de usuários frustrados.
Alarmes CloudWatch
Ter visibilidade e informação é uma coisa, mas ser proativo e saber de antemão que um erro significativo está iminente é outra.
Um alarme do CloudWatch é uma ferramenta de notificação automatizada dentro do AWS CloudWatch que dispara alertas com base em limites definidos pelo usuário, permitindo que os usuários identifiquem e respondam a problemas operacionais, violações ou anomalias nos recursos da AWS monitorando métricas especificadas durante um período designado.
Em nossos painéis, você encontrará exemplos de dois tipos de alarmes:
Alarme para monitoramento de limite de desempenho (duração ou latência)
Alarme para monitoramento de limite de taxa de erro
Alarme de taxa de erro
O código HTTP 5XX significa um erro interno do servidor. Esse erro nunca deve acontecer. É um sinal de que algo inesperado ocorreu; pode ser uma interrupção/problema da AWS ou um bug no código.
Eu defini o limite aqui como um erro 5XX ao longo de 15 minutos, mas você pode defini-lo como quiser (talvez eu tenha sido muito rigoroso).
Alarme baseado em duração
Para problemas baseados em duração, definimos o seguinte alarme na duração P90 para a função Lambda 'create order'. A duração média da função Lambda 'create order' é de 2 segundos, então eu defino o limite do alarme em 3 segundos (3000 ms). Observe que você deve cobrir outras distribuições, não apenas P90 - P99, P95 e média, se desejar fornecer a melhor experiência do usuário para TODOS os seus usuários.

Observe que você pode alterar o widget para exibir um valor numérico singular em vez de um gráfico.
Ações de alarmes
Os alarmes não têm utilidade a menos que tenham uma ação quando disparados.
Configuramos os alarmes para enviar uma notificação SNS para um novo tópico SNS. A partir daí, você pode conectar qualquer assinatura - HTTPS/SMS/E-mail, etc. para notificar suas equipes com os detalhes do alarme para que elas possam reagir e resolver o problema.
Reagindo a alarmes
Quando descobrimos potenciais problemas de desempenho em serviços serverless, principalmente funções Lambda, a solução difere daquela que tínhamos no "antigo" mundo - você não reiniciará um servidor. Você não gerencia a infraestrutura subjacente, e cada problema requer uma pesquisa completa sobre o volume de tráfego, entrada do usuário e configuração Lambda.
Além disso, cada solução requer uma implantação de pipeline de CI/CD, seja para atualizar a configuração da função ou o código (não faça alterações manuais na produção).
Resumo e Código CDK
Isso conclui a primeira parte do post de monitoramento. Abordamos o que é monitoramento de serviço serverless, nossa metodologia para construir um dashboard e fizemos um dashboard para um serviço de amostra.
Na segunda parte desta série de blogs, abordaremos o código do AWS CDK que criou esses painéis e alarmes.
Para aqueles que querem ver o código agora mesmo, clique aqui .