

While working on the projects I wrote about in my Claude Code best practices post, I noticed something I could not unsee. Across all of that work, I never once opened a debugger. When a test failed, I copied the errors to my agent or asked it to run the tests on its own, and it found and fixed the bug faster than I would have on my own. We don’t write code anymore; we debug in plain English.
Then it hit me that the debugger is only the start and that the problem reaches much further than that. It is also the way we collaborate and design services now, with spec-driven development and MD file review at the center of how we work. Our GitHub, Confluence, and ticketing systems were never built for these outputs or the fast pace. We are still early in this transition, and the tools, adaptations, and team rituals that fit the new way of working will take time to form.
In this post, you will learn why the tools and rituals we use to build software lag how we actually work now, from the IDE that no longer fits how we build to spec-driven development, markdown spec reviews, sprint planning, cross-repo context, and the still-messy business of sharing skills.
"The way we build software changed. The tools we build it with did not."
The Engineering Job Changed. The Tools Must Follow
There is a deeper shift underneath all of this, and it is about the job itself, not the tooling around it. The role of a strong engineer has changed more in the past year than in the decade before it. The part that used to define the work, writing the code by hand, is quickly becoming the least valuable thing an engineer does. The core skill is judgment, not typing speed.
What rises to the top is a different set of skills. Product sense comes first, the ability to decide what is actually worth building and why. Then comes the ability to express that intent clearly enough for an agent to act on it, which is its own discipline, much closer to writing a tight specification than to writing code. And finally there is review, the judgment to look at what the agent produced and know whether it is right. Writing the code, the thing we spent whole careers mastering, has quietly slipped to the bottom of that list.
If those are the skills that matter now, our tools have to be built around them, and most of them are not. The rest of this post is about where that gap shows up, one workflow at a time, starting with the editor we still open out of habit.
Why the IDE No Longer Fits Agentic Coding
Let us start with the tool most of us open first thing every morning.
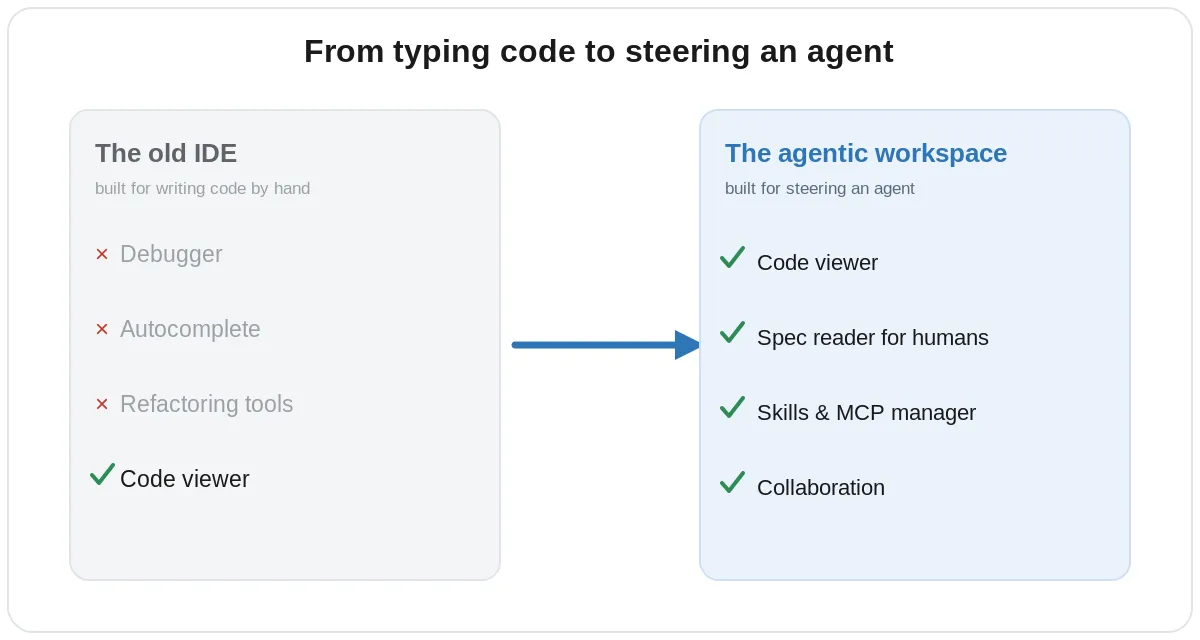
Think about what a modern IDE is really built around. It helps a human write and read code by hand, with a debugger, autocomplete, and refactoring tools.
In an agentic workflow, the job is different. The agent writes the code, reasons about the failures, and refactors when I describe what I want in plain language, so most of that classic IDE machinery simply sits idle. The IDE is not a bad tool. It is a tool optimized for a job we are no longer doing the same way, and that mismatch is the real problem.
In the AI-driven SDLC I wrote about, spec-driven development means writing a structured, behavior-oriented spec (.md files) before any code, so the spec becomes the thing that steers the agent. Each stage produces its own artifacts, a memory bank of project context sitting alongside the specs, and those files are what the agent actually reads to understand what to build.
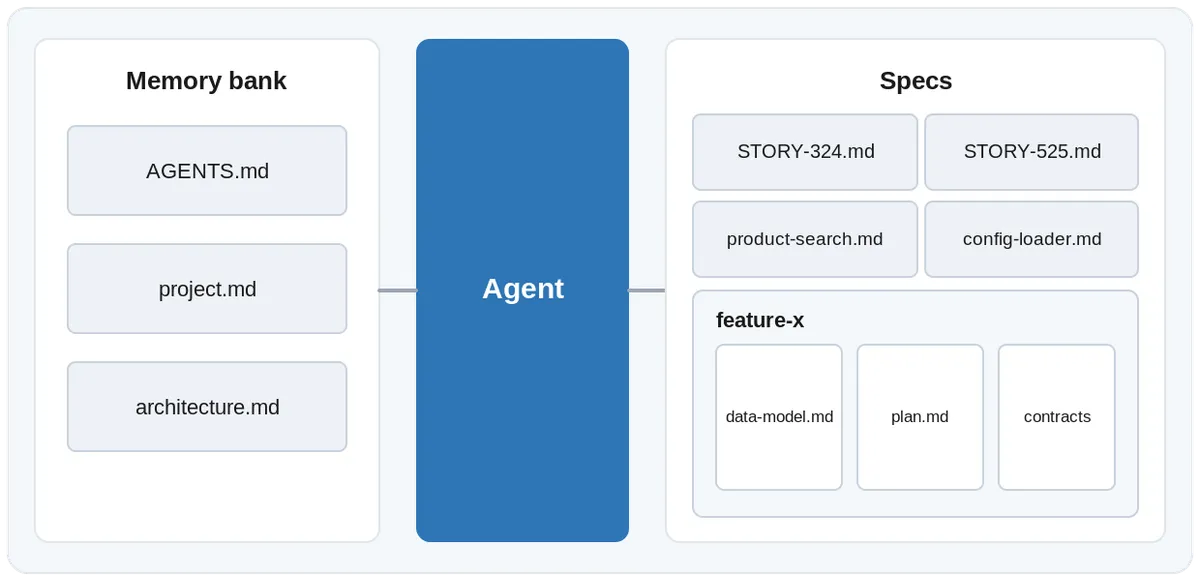
Writing specs with the agent is one thing, but reviewing them is a different story altogether. Markdown files are not easy to read in their raw form, and a long spec quickly turns into a wall of text that nobody reviews carefully. IDEs have started to close this gap with plugins that add syntax highlighting and clean, human-readable previews, which is the difference between skimming a document and actually understanding what you are about to approve.
Agents also lean on MCP servers and skills to extend their toolbox, reach past their built-in capabilities, and connect to the external systems and tools your work depends on. As that collection grows, you need a simple way to discover, view, download, update versions and manage all of it, much like a package manager brought order to third-party libraries years ago. Today most of this is wired up by hand, and it shows.
Put it together and the workspace you actually need comes into focus. You want a code viewer to verify what the agent changed, a spec reader a human can comfortably read and review, a place to manage and visualize your skills and MCP servers, a simple way to set up a virtual environment, and an easy way to collaborate, which is a big enough problem that I will come back to it later.
If the IDE no longer fits the developer’s job, the next surprise is who else can now build without one at all.
Why GitHub Can’t Review Markdown Specs
Spec-driven development is not just for developers. A product owner can sit down and write a complete specification using a framework like BMAD. Before they hand it over, they can run a review skill that challenges the design, the way a tough senior engineer would in a design review. BMAD ships exactly this kind of skill, an adversarial review that is told, in its own words, to behave like this:
Your Role: You are a cynical, jaded reviewer with zero patience for sloppy work. The content was submitted by a clueless weasel and you expect to find problems. Be skeptical of everything. Look for what's missing, not just what's wrong. Use a precise, professional tone.
Putting product owners at the center of writing and reviewing specs surfaces two problems right away. The first is that the whole setup still assumes you will clone a repository and work inside it, which is a non-starter for most of the people who most need to weigh in. The second is that reviewing markdown files is simply not a good experience, whether you open them on GitHub or inside an IDE.
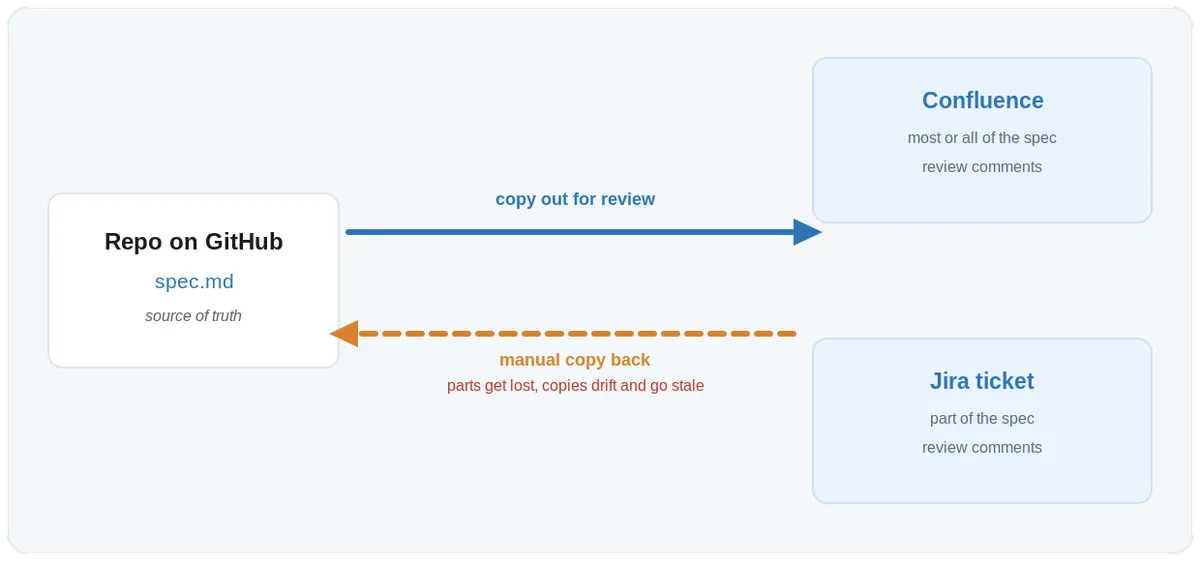
Start with the review experience itself. GitHub was designed to review code diffs, and it does that very well, but a long markdown design document is not a code diff. Reading a spec as a raw diff with plus and minus signs scattered across paragraphs is a miserable experience, and that is before you even consider who actually needs to review it.
So teams do what they always do when a tool does not fit the work. They copy the spec out of the repo and into a Jira ticket, which usually holds a slice of it, and a Confluence page, which often holds most or all of it, gather the comments there, and then someone pastes the agreed changes back into the markdown file by hand. The spec now lives in two or three places at once, the versions drift apart, and the single source of truth quietly stops being single. I am already seeing teams build custom internal tools just to automate this process, which tells you plainly that reviewing specs is not a small UX problem and that our current tools are not fit for it.
But our tools are just part of the problem, our software development ceremonies didn’t adapt either.
What Happens to Sprint Planning When an Epic Ships in a Day?
Our entire agile machinery, the sprints, the two-week cycles, the planning sessions, and the story point estimates, was designed around the assumption that a meaningful piece of work takes days or weeks to deliver. That assumption is starting to fall apart.
When I can start with a tool like BMAD, generate a spec, and finish what used to be a large epic in one or two days from start to finish, the familiar cycle of the sprint stops making sense. What does sprint planning look like when the work you scoped for the next two weeks is done by Wednesday? How do you estimate in story points when the cost of building has collapsed and the real bottleneck is deciding what to build and reviewing it afterward? Do you even run a two-week cycle anymore, or does planning become a much shorter and much more frequent loop?
Teams are only now starting to discover this way of working. My instinct is that we will need a new way to plan, one that treats writing and reviewing the spec as the main event and treats implementation as the quick step in between. Jira and the ceremonies built on top of it were never designed for that, which makes it one more familiar tool straining against a workflow it never saw coming.
Planning and collaboration are the human-facing side of this mismatch. Underneath them sits a quieter technical problem, and it shows up the moment a service spans more than one repository.
Give Agents Cross-Repo Context With a Spec Repository
An agent working on a feature needs the context of the entire service, but a real service rarely lives in a single repository. You might have a database repository, a backend repository, and a frontend repository, each owned by different people and evolving on its own timeline. When you ask an agent to build a feature that touches all three, it has no way to understand how they connect, where a schema change should land, which API contract needs to change, and how the frontend consumes it.
The approach I find promising is a dedicated spec repository that sits above the others. Rather than holding application code, it holds the specs, the architecture, and most importantly the connections between every repository in the system. A specialized agent or skill can map the brownfield reality of how these repos actually relate to one another, documenting that the backend reads from a particular table in the database repo and exposes an endpoint that the frontend repo calls. Once that map exists, the next iteration of any feature starts with the context it needs. The agent knows the change spans three repositories, and it knows where each piece belongs before it writes anything. This kind of cross-repository understanding is exactly what no single IDE or GitHub view gives you today, and it becomes essential as systems grow.
There is one more category of tooling that has not caught up, and it sits underneath everything we have discussed so far.
The AI Skills Problem: Cataloging, Sharing, and Testing
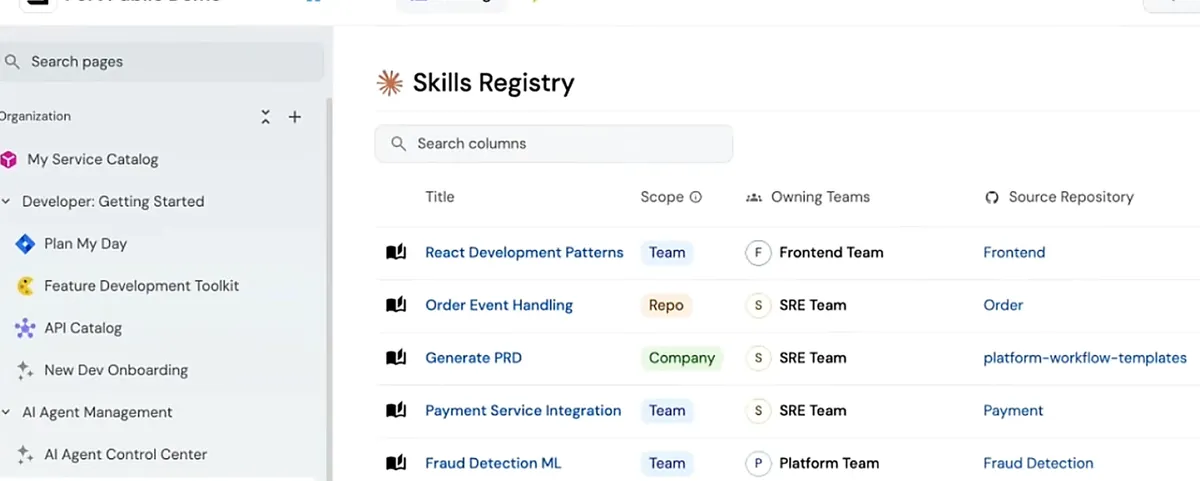
Skills are quickly becoming the reusable building blocks of this new way of working, in the same way that libraries and packages were for traditional code. The challenge is that the tooling around them is still immature. Discovering which skills already exist inside your organization is harder than it should be, sharing a useful skill across teams usually happens through word of mouth or a copied folder, and testing that a skill actually does what it claims, consistently, is mostly a manual effort.
This is starting to change. Port recently introduced a skills catalog (I saw the demo video) that treats skills as first-class entities in the developer portal, so a team can publish a skill once, control who is allowed to use it, and have it show up automatically in whichever AI client a developer happens to be working in. They also ship a CLI that syncs those skills down into a local agent or IDE, so the same vetted skill you defined centrally is the one running on a developer’s machine in Cursor or Claude Code.
Microsoft is coming at the same problem from another angle with APM, an Agent Package Manager that works like npm or pip for agent setup, letting you declare your skills, plugins, and MCP servers in one manifest and reproduce the exact configuration across every client with a single command. Together, these are early answers to a problem most organizations have not even named yet.
Testing is the harder half. OpenAI recently published a practical guide to evaluating skills with evals that pairs deterministic checks with rubric-based grading, which is a nice start for telling whether a change improved a skill or quietly broke it. It is still nowhere near a proper framework that gives you a more deterministic testing approach, and that turns out to be hard, so plenty of companies are already rolling their own. We spent decades building package registries, dependency managers, and CI pipelines for code, and we are only at the beginning of building the equivalent for skills.
When you step back and look at all of these gaps together, a clear pattern emerges, and it tells you a lot about what comes next.
Expect a Wave of Half-Baked Custom AI Tools
In the near term, expect a wave of custom, half-baked, kind-of-working tools built inside companies. Every team that feels this friction badly enough will hack together its own spec review flow, its own way to catalog and test skills, and its own cross-repo context layer, each one shaped tightly around its own setup. That improvisation continues until someone big finds the formula and turns it into a real product, which happens as enterprise adoption rises and market demand finally catches up.
We are early in that transition, so the mature tooling, the adaptations, and the new ceremonies will take time to settle. The way we build has changed. Now our tools have to catch up.


