

Tenant isolation failures are one of the fastest ways to lose customer trust in a SaaS platform, especially when sensitive data is involved. At AWS re:Invent 2025, AWS introduced a new tenant-isolation mode for AWS Lambda to reduce the risk of cross-tenant data exposure in serverless applications.
This post explores the concept of tenant isolation, how Lambda’s tenant isolation mode works, where it helps, where it falls short, and how to decide whether it belongs in your SaaS architecture.
What Is Tenant Isolation in SaaS and Why It Matters
I’ve been building SaaS applications for over 6 years, and if there’s one principle you never compromise on, it’s tenant isolation.
Now imagine this: you wake up to a phone call from an angry customer saying they can see another customer’s data in your service. That’s not just a bug, it’s a catastrophic failure. Incidents like this can permanently damage trust, trigger compliance nightmares, and in some cases end a company’s reputation altogether. For security-focused companies, the stakes are even higher.
Customers trust you with their most sensitive data and they expect you to protect it.
In practice, properly isolating tenant data isn’t always trivial. As SaaS architectures grow in complexity, tenant isolation requires deliberate design choices and a deep understanding of how your infrastructure actually behaves in production.
SaaS Tenant Isolation Models: Pool vs. Silo
The more you move customers into a multi-tenant model, the more they will be concerned about the potential for one tenant to access the resources of another tenant. SaaS systems include explicit mechanisms that ensure that each tenant’s resources — even if they run on shared infrastructure — are isolated. — AWS
When we talk about customer (tenant) isolation in SaaS systems, there isn’t a single “correct” approach. Instead, there are several well-known models — each with its own trade-offs. In fact, comparing these models in depth could easily be a blog post on its own.
At a high level, tenant isolation decisions usually fall into two domains: compute and data.
On the compute side, you need to decide whether tenants share compute resources.
In a pooled model, requests from all tenants are handled by the same compute layer — for example, the same EC2 instances or AWS Lambda functions. In more isolated models, tenants may have dedicated compute resources, reducing the blast radius at the cost of greater complexity and higher costs.
On the data side, the same question applies. Tenants can share a single database or table, with tenant identifiers used to logically separate data. Alternatively, each tenant can have its own table, schema, or even an entirely separate database or cluster. These choices have a significant impact on data modeling, query complexity, performance isolation, tenant lifecycle operations (onboarding and offboarding), and cost differentiation between customers. Each combination of compute and data isolation comes with clear pros and cons affecting everything from operational overhead to scalability and security guarantees.
That said, it’s important to be very clear about one thing: no isolation model is immune to mistakes. Silo architectures can create a false sense of security. Even with dedicated infrastructure, bugs still happen — incorrect configuration, or faulty authorization logic can all lead to cross-tenant access. Code can point to the wrong database, and routing errors can still cause tenants to share execution paths unintentionally.
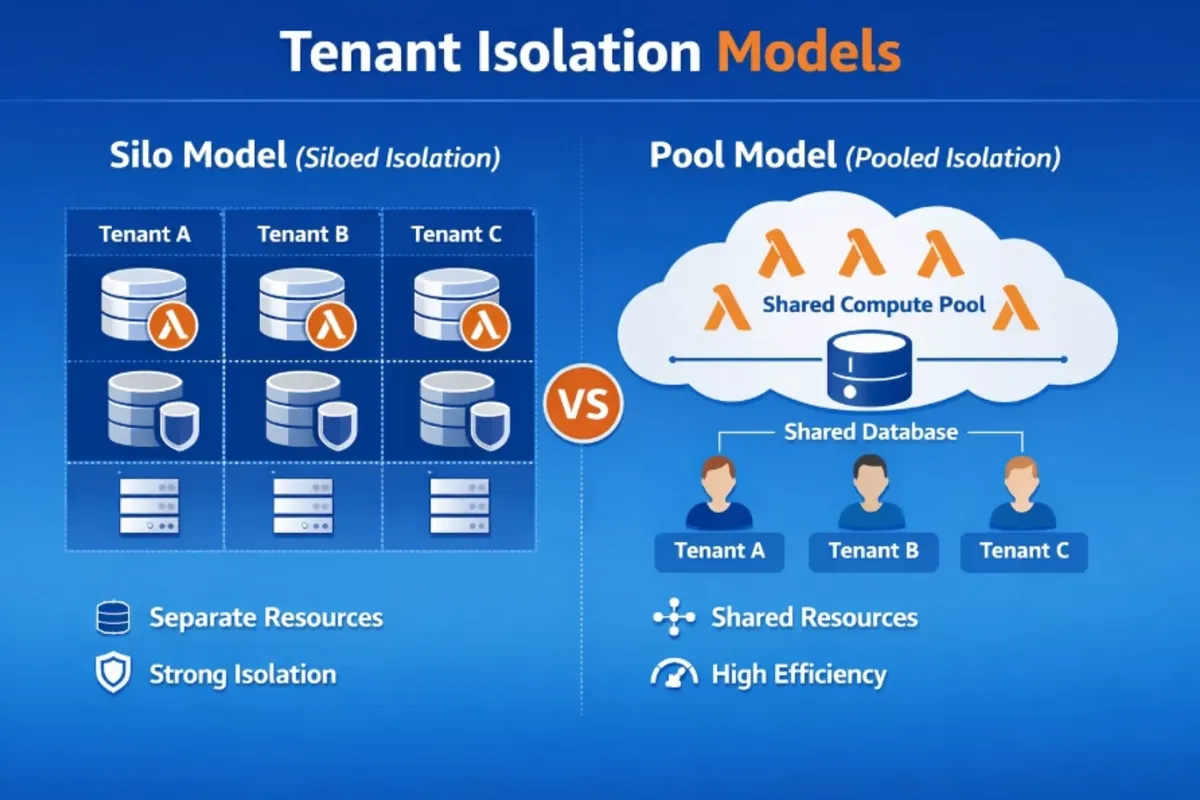
There is also a hybrid model that combines siloed and pooled resources. In this approach, high-value customers may receive dedicated silos, while others share pooled infrastructure, or different service tiers (such as regular and premium) are isolated into separate silos.
Pool Model for Tenant Isolation and Lambda Functions
So, which tenant isolation model should you choose when working with Lambda functions?
In the silo model, you need to create separate functions per tenant, duplicating code across many tenants. While this approach improves isolation, it significantly increases operational overhead and complexity from deployment and observability perspectives as you add more tenants to the system.
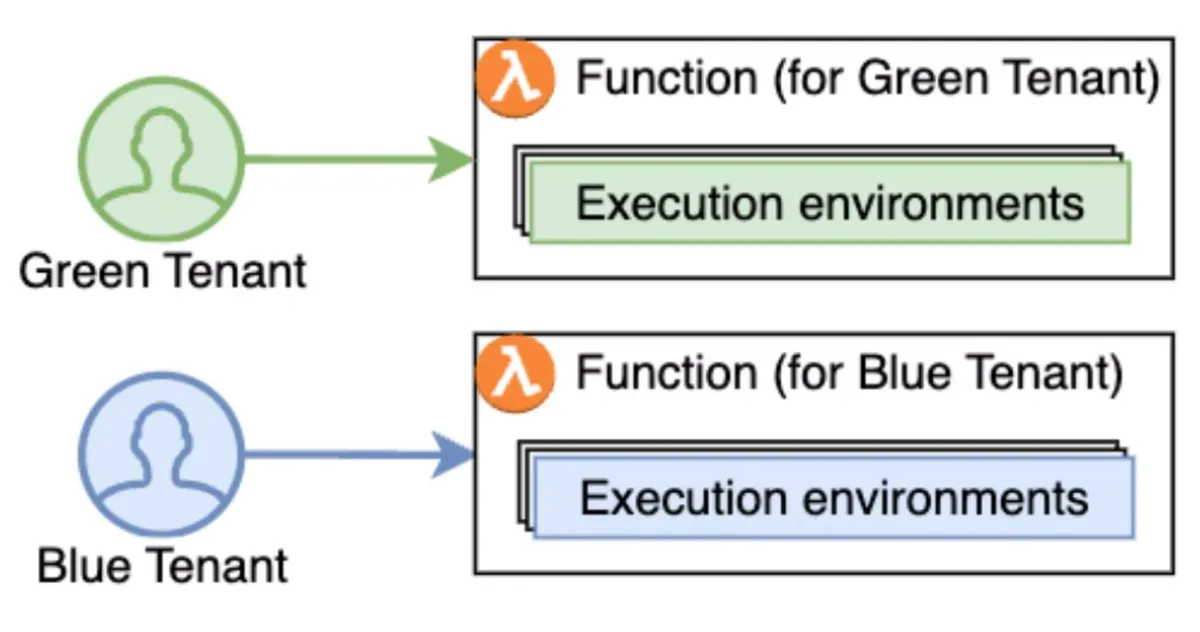
In a pooled compute model, multiple tenants share the same Lambda function and execution environment. While AWS guarantees request-level isolation, the responsibility for tenant isolation inside the application remains entirely with you. More on that below.
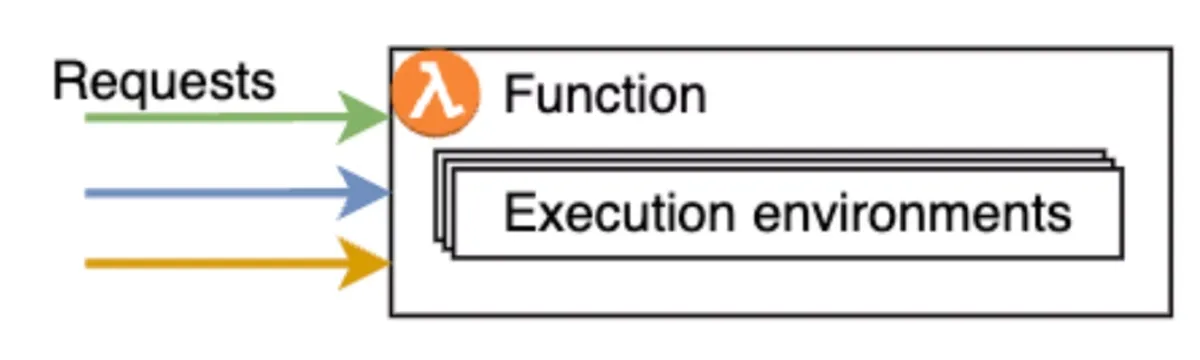
Security Risks of Multi-Tenant AWS Lambda Functions
The pool model introduces several potential security risks that span over two access patterns:
- State leakage: access to local function global variables or memory.
- Data leakage: access to the data/resource layer, a.k.a the customer’s resources.
State leakage occurs when tenant-specific data stored in global variables, in-memory caches, or improperly scoped SDK clients unintentionally persists across invocations. This can also happen when environment variables, configuration files, or runtime secrets are shared across tenants. To prevent this, developers must carefully manage shared state by avoiding global storage, clearing sensitive data after each invocation, or consistently scoping access using a tenant-specific identifier (using tenant_id as an hash key for example).
A Lambda function’s execution role must have permission to access tenant resources, and because the same function serves requests from all tenants, it typically requires access to data belonging to every tenant. Whether data is stored in separate tables or in a shared schema, the function is technically authorized to read and write across tenants. As a result, a coding mistake can lead to accidental cross-tenant access. This class of vulnerability is best described as over-permissive IAM permissions.
In both cases, it’s possible to avoid mistakes if you know what you are doing.
But as you scale your development force or use AI without the proper skills or guardrails, mistakes can and will happen.
Luckily, just ahead of AWS re:Invent 2025, AWS announced a new tenant isolation mode for AWS Lambda to address these challenges.
Let’s see if they got it right, and what can be done in addition to their solution.
How AWS Lambda Tenant Isolation Mode Works
Enabling customers to isolate request processing for individual tenants or end-users invoking a Lambda function — AWS
The idea sounds promising. You tell AWS which tenant_id the current Lambda function invocation belongs to, and they make sure that every tenant gets its OWN execution environment! No two tenants will share the same environment and each execution environment can be reused to process requests coming from the same tenant again.
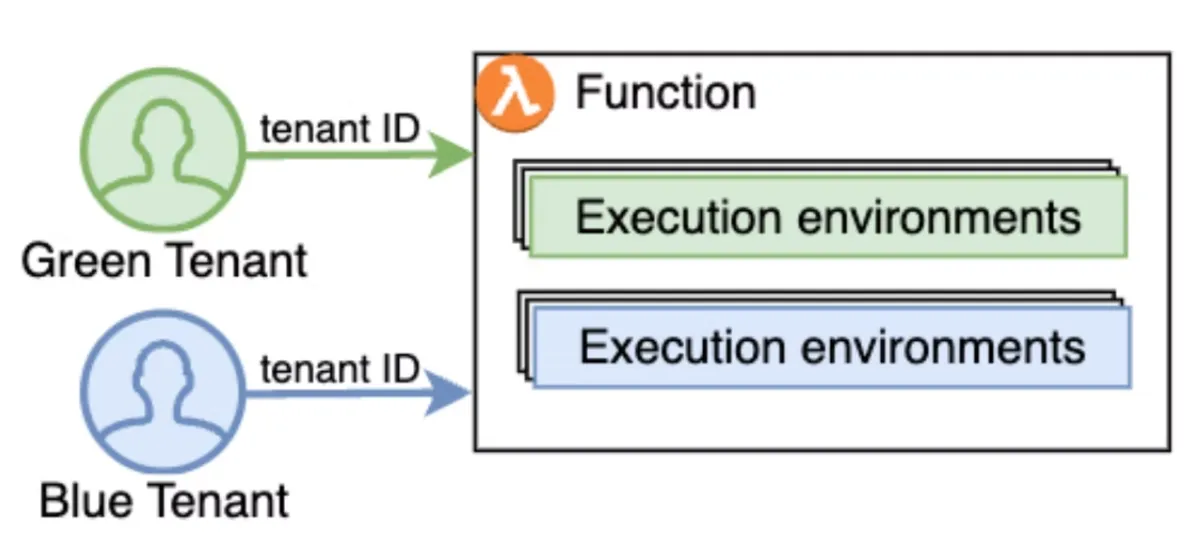
What AWS Lambda Tenant Isolation Mode Solves
Tenant isolation mode directly addresses the first risk by ensuring that tenants do not share execution environments, effectively eliminating the possibility of state or storage leakage. By design, AWS removes this entire class of developer error.
As an added benefit, the Lambda context now includes the tenant_id, making it easy to log and reuse across your application. While this is a nice touch, most mature SaaS platforms already expose the tenant identifier through a shared utility or context object.
However, these benefits only apply when the feature is configured correctly. From an infrastructure perspective, enabling isolation is as simple as setting a flag in your IaC. At runtime, though, you must integrate it properly. This is done by using a Lambda authorizer to ensure that tenant identity is properly set.
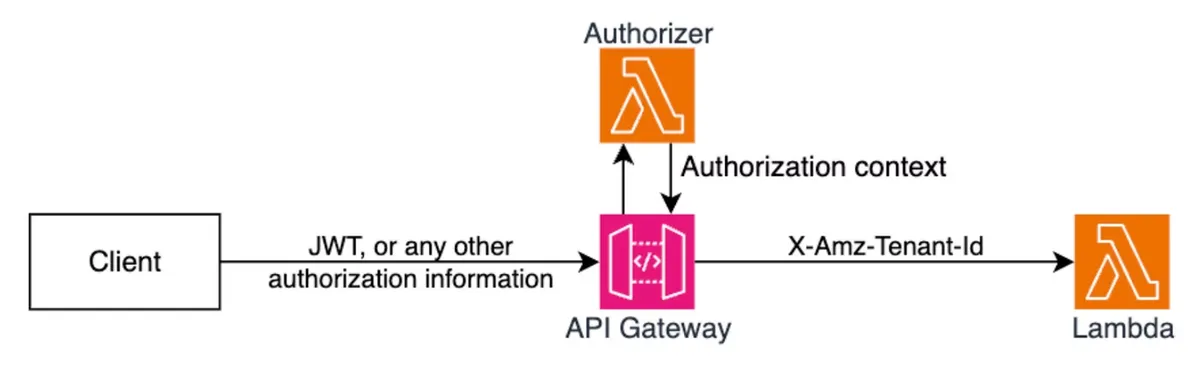
The Lambda authorizer needs to validate the tenant request, extract the tenant_id, and add the special, cool new header ‘X-Amz-Tenant-Id’ that marks the tenant_id for Lambda to use in the isolation mode. You should also verify that you don’t get this header from the client for obvious security reasons.
For sample implementation, check out AWS’s GitHub sample repo.
Lets go over the pros and cons of this mode.
Pros and Cons
| Statement | Detail |
|---|---|
| ✅ Execution environment isolation | Solves the first security risk — each tenant gets its own execution environment |
| ✅ Built-in observability | Tenant_id field is added to CloudWatch logs and Lambda context object |
| ❌ Data access risk remains | Does NOT solve the second security risk. We still need to figure out a fine-grained IAM approach (more on that below) |
| ❌ Extra cold starts | Your application may experience a higher percentage of cold starts, as Lambda processes requests in separate execution environments for each tenant. You also need to be aware of and follow your maximum concurrent invocation quota (you might reach it) |
| ❌ Additional cost | You pay a fee for each new tenant-specific execution environment created, depending on the memory configured for your function. See the Lambda pricing page for details |
| ❌ Developer experience | You need to add an authoriser and use the same one across all your services. If there’s a mistake and the value of ‘X-Amz-Tenant-Id’ is incorrect, the entire feature is broken. I suggest moving the code and its IaC configuration to a centralised, audited internal library where developers can reuse it and enjoy peace of mind |
What Lambda Tenant Isolation Mode Does Not Solve
As mentioned above, security risk number is not resolved. We still need to figure out fine grained IAM approach. To be fair, AWS has provided plentiful guidelines and best practices to solve this. Going back to Bill Tarr’s legendary’s article “Isolating SaaS Tenants with Dynamically Generated IAM Policies” and the excellent article by Anton Alexandrov and Ayush Kulkarni — “Building multi-tenant SaaS applications with AWS Lambda’s new tenant isolation mode”, both give you guidelines on how to solve it. But the point is, you still need to do it by yourself and make sure your developers use your solution and don’t bypass it. Bypassing can lead to tenant isolation mistakes.
Fun fact, I did a webinar with Bill and Anton (who are dear friends!) about how we solve tenant isolation at CyberArk, a Palo Alto Networks company, where I walked through the custom library code that solves this issue.
Here’s the tl;dr from the webinar:
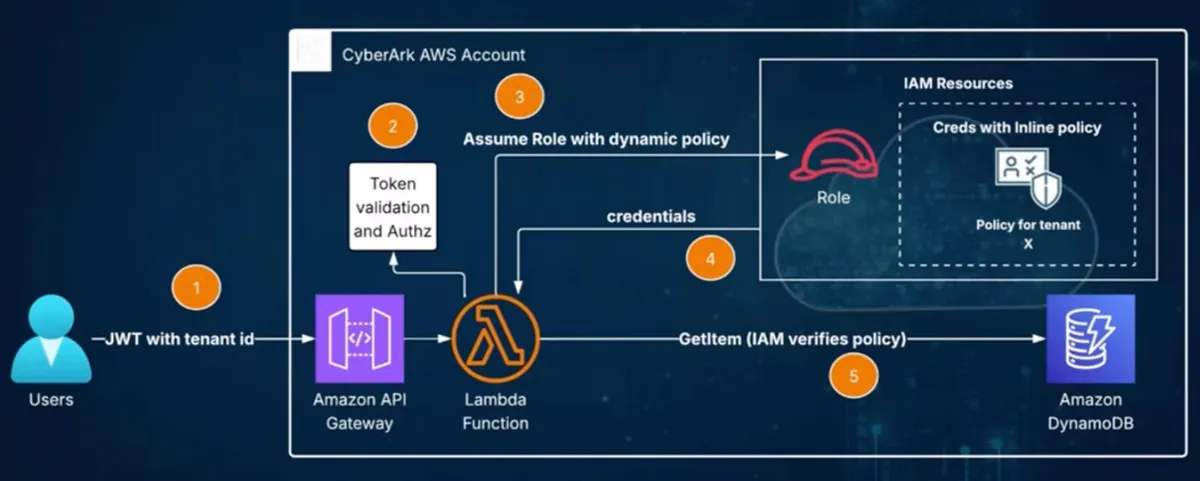
Let’s assume we have a Lambda function that needs to read data from a shared DynamoDB table, where all tenants share the table, but tenant_id and other attributes differentiate items.
The Lambda function runs with a role that cannot access the DynamoDB table, not read, not write, nothing. It will gain access using a special custom library code that assumes a role with the required access.
Let’s follow the diagram flow:
- User sends a request to the API with a JWT that includes their tenant identity.
- The Lambda function validates the token and checks for authorization, then extracts the tenant information.
- The Lambda function uses the library to assume an IAM role with read permissions on the table and across all tenants. But there’s a catch: the library code adds an inline policy that is dynamically scoped to the current tenant (for example, row-level security for DynamoDB). It limits the scope, that’s the neat trick!
- AWS Security Token Service issues temporary credentials that are restricted to accessing only that tenant’s resources.
- The Lambda function can retrieve an item from the table. If it tries to access another tenant’s information, an IAM exception is raised.
This is the solution that solves security risk number two, but it has limitations — if your developers don’t use this approach and access the table directly, then it’s worthless. You still need to rely on the human factor here.
BTW, if you want to understand the flow in depth, please read Bill’s article or watch the webinar at the 51:00-minute mark.
In addition, in Anton’s article, they mention that you can also do the assume role part inside the Lambda authorizer itself (along with the inline policy and tenant id), store them in cache per tenant ID (in memory cache, etc.), and pass the credentials to the function along with the ‘X-Amz-Tenant-Id’ header. Then, the function can create a new AWS SDK client based on those credentials and access the tenant’s resources. However, I’m not sure that’s a good practice if multiple functions use the same credentials.
Should YOU Use Tenant Isolation Mode?
I really appreciate how AWS listens to its customers and invests in solving complex, high-impact security problems, such as tenant isolation. I was fortunate to provide early feedback on this feature to the Lambda team, and it’s great to see that input reflected in the final design.
That said, this feature isn’t for everyone. If your organization isn’t willing to invest additional budget in security, you’re probably not the target audience. And if you’ve already built a mature ecosystem of internal libraries and tooling around tenant isolation in Lambda, you may find limited immediate value — especially since this model doesn’t fully eliminate access-control risks and requires migration, along with carefully implemented authorizers that must be shared and maintained across the organization.
However, for teams looking for stronger guardrails and greater peace of mind — especially those aiming to reduce developer mistakes — this feature is a solid option and a meaningful step forward.
Looking ahead, I really hope a v2 is already in the works.
Ideally, Lambda invocations would start with a role that already includes the correct, tenant-scoped inline policy, with the tenant ID injected by the platform — without relying on custom authorizers to assume roles at runtime. With built-in policy templates and native enforcement, this could significantly improve both security and developer experience.
If that becomes a reality, I’d migrate my workloads to this model immediately. I’m more than willing to pay extra for stronger security guarantees and better DevEx — and I know many platform teams feel the same way.


